Kotlin版本的多线程下载与Java版本的不同点主要在线程控制方面,Java是通过线程池来控制,而Kotlin版本则利用异步协程创建时传入”Dispatchers.IO“来使用多线程,并利用父协程会等待子协程执行完毕这点来简化协程/线程控制。
建议新建Spring boot项目并选择Kotlin,并将kotlin协程依赖加入,pom.xml主要内容如下:
...
<properties>
<java.version>1.8</java.version>
<kotlin.version>1.3.40</kotlin.version>
</properties>
<dependencies>
<dependency>
<groupId>org.jetbrains.kotlinx</groupId>
<artifactId>kotlinx-coroutines-core</artifactId>
<version>1.2.2</version>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>
</dependencies>
...
Kotlin多协程/多线程下载文件完整代码如下:
package me.kagura
import kotlinx.coroutines.Dispatchers
import kotlinx.coroutines.async
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
import org.jsoup.Connection
import org.jsoup.Jsoup
import org.slf4j.LoggerFactory
import java.io.File
import java.io.InputStream
import java.io.RandomAccessFile
fun main() {
val log = LoggerFactory.getLogger("https://Kagura.me")
val url = "https://www.baidu.com/img/bd_logo1.png"
//文件全路径
val targetPath = "baidu.png"
//指定协程数量
val coroutinesCount = 3
//缓存大小
val bufferSize = 500
//获取文件总长度
val contentLength = getContentLength(url)
log.info("将要使用:$coroutinesCount 个协程下载总长度为:$contentLength 的URL:$url")
runBlocking {
val job = launch {
repeat(coroutinesCount) {
//注意,必须是"Dispatchers.IO"才会用多线程
async(Dispatchers.IO) {
val start = it * contentLength / coroutinesCount
var end = (it + 1) * contentLength / coroutinesCount
end = (if (end >= contentLength) contentLength else end) - 1
log.info("第$it 个协程负责下载的区间为:$start - $end")
val inputstream = getRangeInputstream(url, start, end)
downloadFileWithRange(inputstream, targetPath, start, end, bufferSize, it)
}
}
}
//通过启动父协程来启动子协程,利用父协程会等待子协程完成这点
job.start()
}
log.info("完成下载总长度为:$contentLength 的URL:$url")
log.info("完整文件路径为:${File(targetPath).absolutePath}")
}
/**
* 获取指定区间输入流
* 注意超时时间长一些
*/
fun getRangeInputstream(url: String, start: Long, end: Long): InputStream {
return Jsoup
.connect(url)
.ignoreContentType(true)
.header("Range", "bytes=$start-$end")
.timeout(9999999)
.execute()
.bodyStream()
}
/**
* 读取指定URl的"Content-Length"头
* 因为只需要读取Header所以发送"HEAD"请求即可
*/
fun getContentLength(url: String): Long {
return Jsoup
.connect(url)
.ignoreContentType(true)
.method(Connection.Method.HEAD)
.execute()
.header("Content-Length")
.toLong()
}
/**
* 根据指定的输入流下载到文件并输出进度信息
*
* @param input 要下载的输入流
* @param targetPath 要保存到的文件
* @param start 下载区间Range的起始位置,仅用于日志输出
* @param end 下载区间Range的结束位置,仅用于日志输出
* @param bufferSize 缓存大小
* @param coroutineID 标记当前协程,仅用于日志输出
*/
fun downloadFileWithRange(input: InputStream, targetPath: String, start: Long, end: Long, bufferSize: Int, coroutineID: Int) {
val log = LoggerFactory.getLogger("https://Kagura.me")
var sizeRange = end.toDouble() - start
var output = RandomAccessFile(targetPath, "rwd")
output.seek(start)
try {
input.use { input ->
output.use {
var sizeRead = 0
var read = ByteArray(bufferSize)
var len = 0
while (input.read(read).also { len = it } != -1) {
it.write(read, 0, len)
sizeRead += len
val ratio = String.format("%.2f", (sizeRead * 100 / sizeRange))
log.info("第${coroutineID}个协程负责下载进度为$ratio")
}
}
}
} catch (e: Exception) {
e.printStackTrace()
}
}
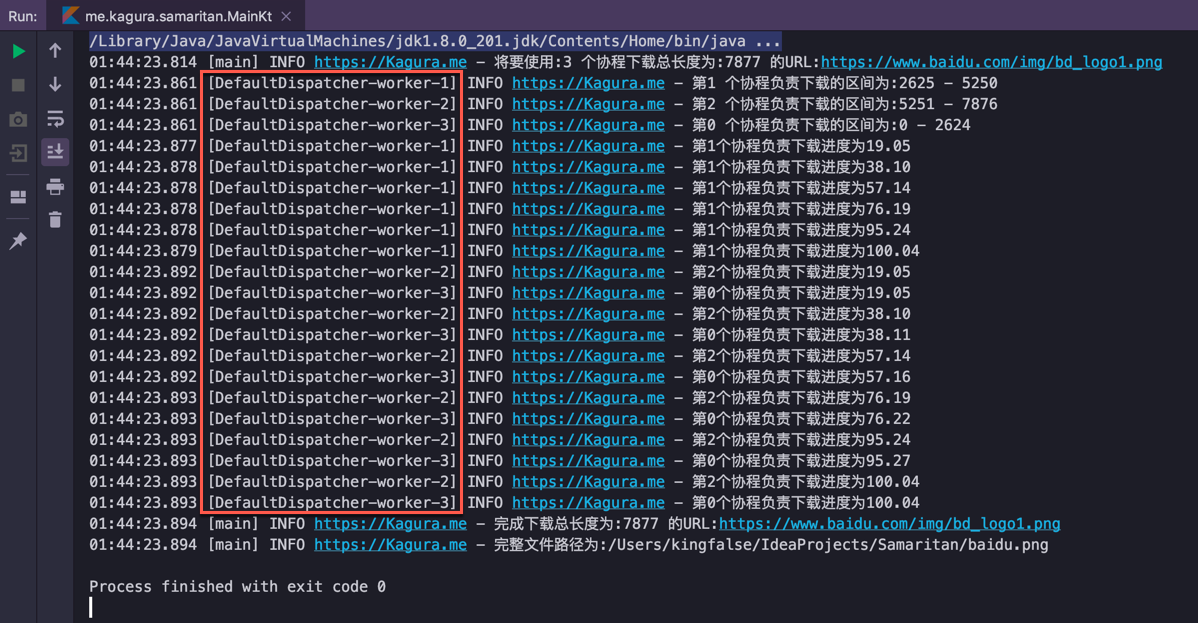
实际运行效果如下图,以下载百度首页logo为例。注意图中红色框内为运行时的实际线程名。
未经允许不得转载:鹞之神乐 » Kotlin多协程/多线程下载文件

 如何快速编写一个暗网爬虫
如何快速编写一个暗网爬虫

这分段下载有问题啊….我测试下载了一个gif图,用你的方法下载的文件长度比原来的要小,虽然可以正常打开,但gif图片有几帧会出现部分黑屏
gif地址:https://img2020.cnblogs.com/blog/1210268/202004/1210268-20200413161422035-1188549898.gif
使用jsoup 1.13.1就没有问题了….
下大文件(70M左右)会卡住…